
Welcome to the Darwin Derby
Karpathy's autoresearch pattern applied to anything

Last week Andrej Karpathy published a github repo called autoresearch which he used to autotune his nanochat project to generate and run experiments. It’s a simple loop that just has an agent try a new experiment, measure the results, and discard it if it is worse than the current best. If it is better than the current best, it is accepted.
So as long as you have a solid enough measure of “better”, you can just spray experiments all over the place and ratchet up your implementation as you find improvements. It’s got a nice property of always getting better, but it’s also not a hill-climbing process so it’s not as prone to getting stuck at local optima.

The Darwin Derby is just the generalization of this idea. It is a thin framework for taking anything that can be measured, and letting you auto-tune that with an agent, or swarm of agents.
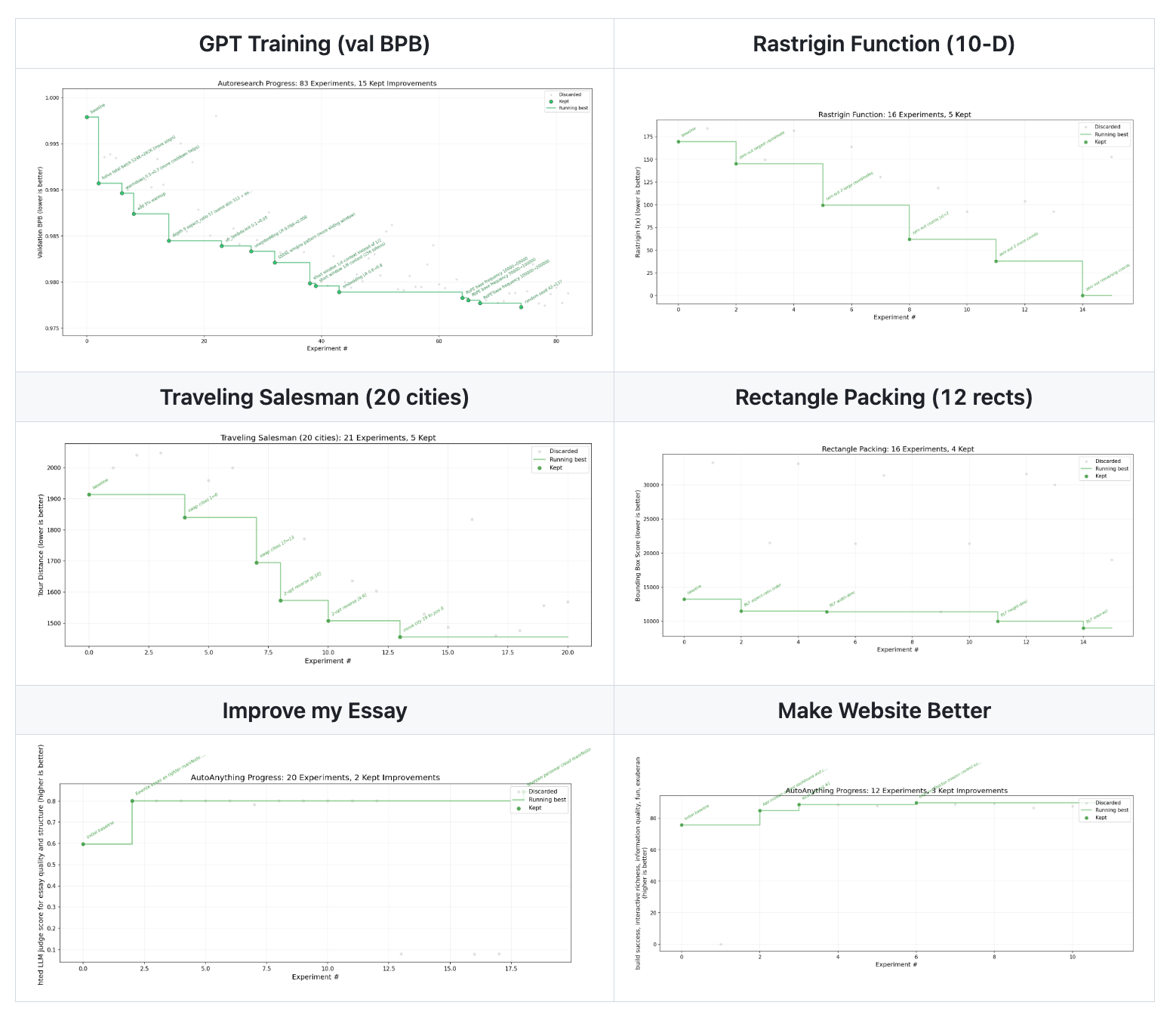
Karpathy’s loop is ML specific and validates against a bits-per-byte metric. But we can really just as well understand any bag of data as value-able on any numerical range, and climb our way to glory, given enough tries.
What’s cool is that since LLMs can vibe-score things, we can really start to just focus on the things we value, and have the manifestation of those values get vibed into being by a swarm of Ralph-spirited agents. Since Ralphs are dumb and abundant we can just send them into any remotely interesting search spaces, and reap the rewards when they come.

We were previously in a regime where we only thought to optimize objective measures. Now we’re in a regime where we can optimize anything that can be judged, so long as those judgements are somewhat mechanical and numerical.
Of course we know Goodhart’s law, that overpowered metrics eat underspecified goals, and that if you only value paperclips you might turn the universe into them. But at the same time, the biological fitness function has apparently ratcheted its way from bacteria to fish to monkeys building artificial intelligences on lithographic semiconductors.
There’s something cool about choosing objective functions and seeing what “features” emerge over a historical lineage. Eyes are thought to have evolved independently more than once, whales still technically have feet, etc. On the spectrum of central intelligent design and natural selection, our current digital artifacts and tools are all turned toward design. But what we are faced with over the next decades is the notion that our digital stuff will grow and evolve more like animal populations.
Trying it out
Darwin Derby is a relatively light set of conventions that if you follow, we can automatically run an evolutionary process over. To install and try it:
uv tool install darwinderby
derby try fib # try a demo optimizationCreate your own problem
Follow the walkthrough in create-problem.md. The short version:
derby init my-problem --direction minimize
cd my-problem
# Edit three things:
# problem.yaml — describe the problem
# state/ — put whatever files agents should optimize
# scoring/score.py — implement your scoring function
derby run -a "claude -p 'read agent_instructions.md and improve the solution'"Learn more
README — full CLI reference and how the system works
create-problem.md — guide to creating new problems
scoring.md — guide to creating scoring functions
darwinderby.md — design philosophy and principles
A key idea is that agents never see the scoring code, so they can’t game it — they just push changes and get back a number.

Listen to Vulpeck’s Darwin Derby here.
There is no reason we can't evolve software via agents:
- today tokens are expensive but models are becoming faster, cheaper, better
- software engineering is moving quickly toward automation
- evolutionary models are highly applicable to engineering
Even Google is exploring evolutionary engineering with AlphaEvolve:
https://deepmind.google/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/
Great post and I am looking forward to reading more from you!